Serving Models and Open-source LLMs¶
Both Hugging-face and MLFlow models as well as LLM models can be deployed in DKubeX. For the steps required to serve the particular type of models, please click on the appropriate link beside the descriptions given below.
Description |
Reference |
|---|---|
Deploying models registered in MLFlow in DKubeX |
|
Deploying models from Huggingface repo |
|
Deploying LLM registered in DKubeX |
Deploying models from MLFlow¶
The registered models in the Models page in MLFlow in DKubeX can be deployed.
On the DKubeX Workspace, click on the terminal application to open the DKubeX CLI on a new tab.
Type the following command while replacing with the appropriate details enclosed in hashes.
d3x serve create -n <deployment name> -r mlflow --model <model name> --model_version <model version number> --repo_name <name of repo containing serving script> --repo_org <username of repo owner> --is_private_repo --access_token <your github personal access token> --branch_name <name of the branch containing the serving script> --depfilepath <deployment file path> --ngpus <number of gpu> --min_cpu <min number of cpus for cluster creation> --max_cpu <max number of cpus for cluster creation> --min_memory <min memory for cluster creation> --max_memory <max memory for cluster creation> --min_replicas <min number of deployment replicas> --max_replicas <max number of deployment replicas>
d3x serve create -n fmnistdeploy -r mlflow --model fmnistmodel --model_version 1 --repo_name dkubex-examples --repo_org dkubeio --branch_name serve --depfilepath fashion_mnist.deploy
Note
In the serving command, if the values of hardware type, cpu, gpu, memory and replica are not provided, it automatically accepts the default values for them.
Use –is_private_repo and –access_token flags if the repository containing the serving script is private. Also make sure that you have access to the repository containing the serving script.
To find the model name and version number, use the following steps-
Open the MLFlow tab on DKubeX UI.
Open the Models page in MLFlow. This will show the list of all registered models.
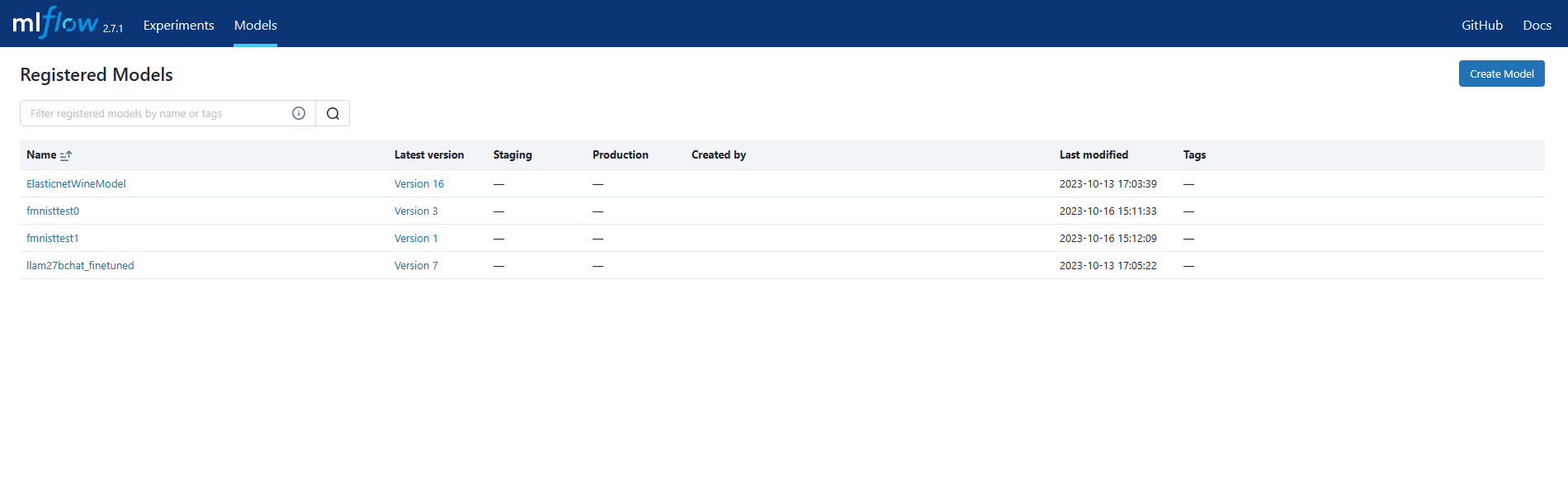
Note down the name and the version number of the model you are going to deploy.
After entering all necessary details, press Enter. The deployment creation will start automatically.
On the DKubeX UI, go to the Deployments tab. The list on the screen should show your deployment, along with it’s status, the name of the serve cluster and the serve endpoint.
The endpoint will show up after the deployment is successful, and the status turns to running.
Clicking on the name of the deployment opens the page containing all the details of that particular deployment.
Clicking on the name of the serve cluster opens the Ray dashboard for that cluster.
Deploying Hugging-face models¶
Pre-trained models available in Hugging-face can be deployed by DKubeX.
On the DKubeX Workspace, click on the terminal application to open the DKubeX CLI on a new tab.
Type the following command while replacing with the appropriate details enclosed in <>.
d3x serve create -n <deployment name> -r hugging_face --hface_repoid <repo-id> --hface_tokenizer <tokenizer> --hface_classifier <classifier> --repo_name <name of repo containing serving script> --repo_org <username of repo owner> --is_private_repo --access_token <your github personal access token> --branch_name <name of the branch containing the serving script> --depfilepath <deployment file path> --ngpus <number of gpu> --min_cpu <min number of cpus for cluster creation> --max_cpu <max number of cpus for cluster creation> --min_memory <min memory for cluster creation> --max_memory <max memory for cluster creation> --min_replicas <min number of deployment replicas> --max_replicas <max number of deployment replicas>d3x serve create -n biogptdeploy -r hugging_face --hface_repoid microsoft/biogpt --hface_tokenizer BioGptTokenizer --hface_classifier text-completion --repo_name dkubex-examples --repo_org dkubeio --branch_name serve --depfilepath biogpt.deploy
Note
In the serving command, if the values of hardware type, cpu, gpu, memory and replica are not provided, it automatically accepts the default values for them.
Use –is_private_repo and –access_token flags if the repository containing the serving script is private. Also make sure that you have access to the repository containing the serving script.
To find the Hugging-face repo ID, tokenizer and model classifier, use the following steps-
Open the model’s page on the Hugging-face website.
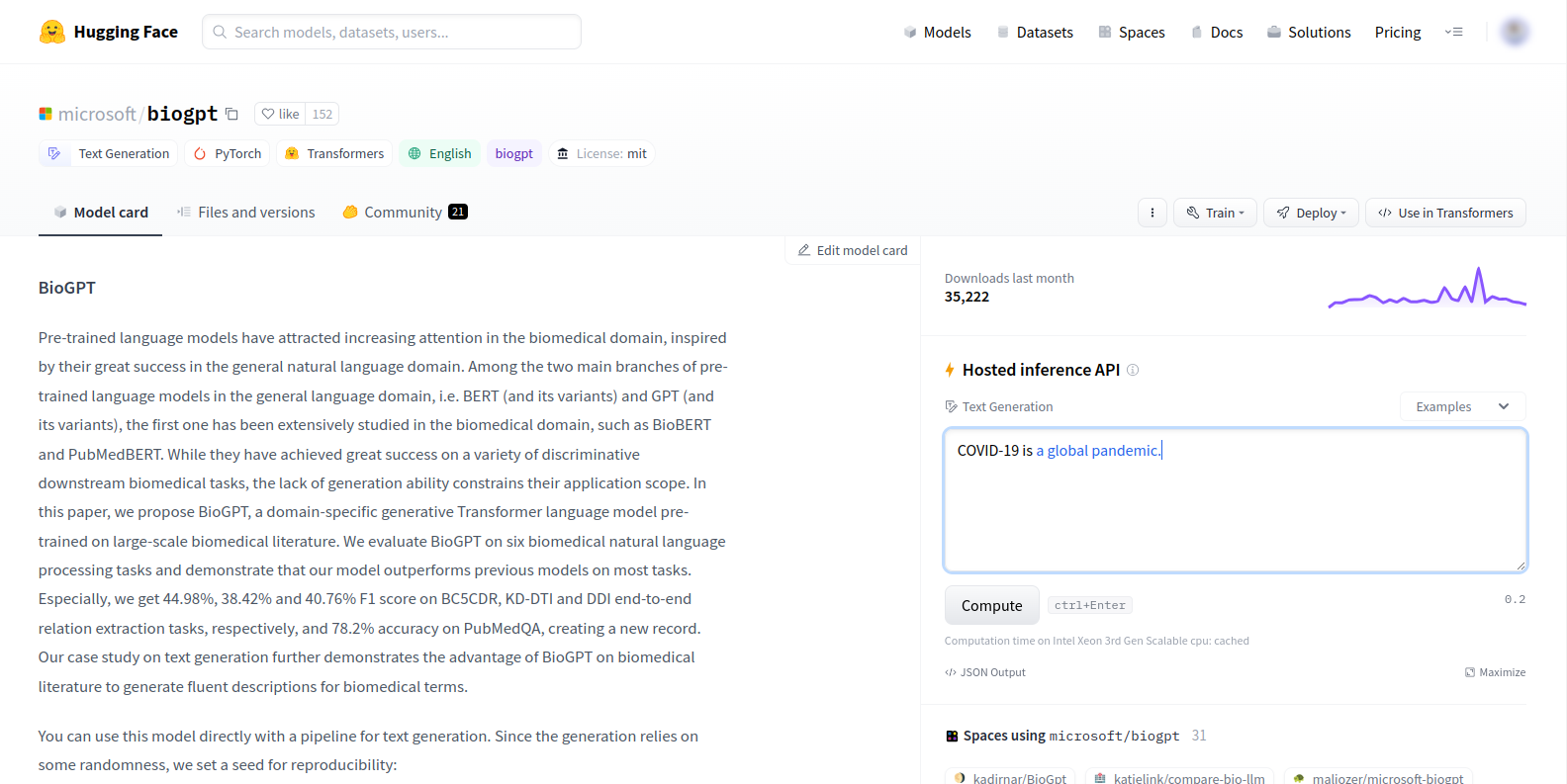
Click on the Copy model name to clipboard button next to the name of the model name. This copies the model repo ID to the clipboard. Make a note of it in a text editing software to use it later.
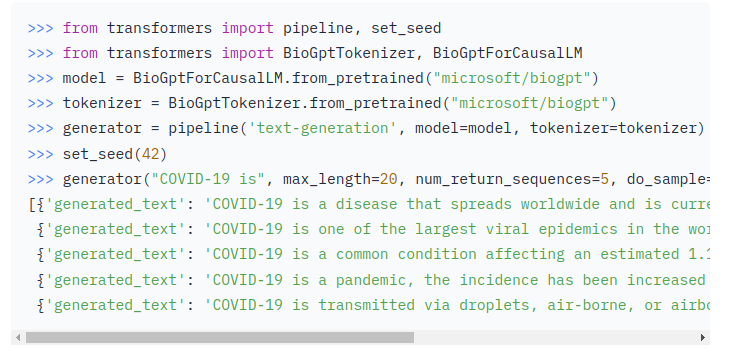
In the model description, from the sample code provided, you can find the tokenizer for the model. For this example in the next photo, the tokenizer is BioGptTokenizer. Make a note of it.
For the model classifier, check the first tag below the name of the model. This is the model classifier. Make a note of it too.
After entering all necessary details, press Enter. The deployment creation will start automatically.
On the DKubeX UI, go to the Deployments tab. The list on the screen should show your deployment, along with it’s status, the name of the serve cluster and the serve endpoint.
The endpoint will show up after the deployment is successful, and the status turns to running.
Clicking on the name of the deployment opens the page containing all the details of that particular deployment.
Clicking on the name of the serve cluster opens the Ray dashboard for that cluster.
Deploying LLMs in DKubeX¶
Both base and finetuned LLMs can be deployed in DKubeX. The steps to deploy them are given below.
Deploying Base LLMs¶
You can deploy base LLMs which are registered with the DKubeX LLM Registry and base LLMs available on the Huggingface repository.
To list all base LLMs registered with DKubeX, use the following command.
d3x llms listInformation
To see the full list of LLMs registered with DKubeX LLM Registry, please visit the List of LLMs in DKubeX LLM Catalog page.
To deploy a base LLM registered with the DKubeX LLM registry, use the following command. Replace the parts enclosed within <> with the appropriate details.
Note
In case you are using a EKS setup, please change the value of the flag --type from a10 to g5.4xlarge in the following command.
d3x llms deploy --name <name of the deployment> --model<LLM Name> --type <GPU Type> --token <access token for the model (if required)>
d3x llms deploy --name llama27b --model meta-llama--Llama-2-7b-chat-hf --type a10 --token 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
You can check the status of the deployment from the Deployment page in DKubeX or by running the following command.
d3x serve list
You can deploy base LLMs not available in the DKubeX LLM Registry from the Huggingface repository. Replace the parts enclosed within <> with the appropriate details.
Attention
Make sure you have provided the deployment configuration file for the LLM that you want to deploy in your workspace.
Note
In case you are using a EKS setup, please change the value of the flag --type from a10 to g5.4xlarge in the following command.
d3x llms deploy --name <deployment name> --config <path to deployment config file> --type <GPU type> --token <access token for the model (if required)>
d3x llms deploy --name llama213b --config /home/ocdlgit/llama213b.yaml --type a10 --token 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
You can check the status of the deployment from the Deployment page in DKubeX or by running the following command.
d3x serve list
Deploying Finetuned LLMs¶
You can deploy LLMs finetuned and saved in your workspace, or you can also deploy finetuned LLMs registered in MLFlow in your workspace.
To deploy a finetuned LLM saved in your workspace, use the following command. Replace the parts enclosed within <> with the appropriate details.
Note
In case you are using a EKS setup, please change the value of the flag --type from a10 to g5.4xlarge in the following command.
d3x llms deploy -n <name of the deployment> --base_model <base LLM name> -m <absolute path to the finetuned model> --type <GPU type> --token <access token for the model (if required)>
d3x llms deploy -n llama27bft --base_model meta-llama--Llama-2-7b-chat-hf -m /home/ocdlgit/finetuned_llama27b --type a10 --token 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
You can check the status of the deployment from the Deployment page in DKubeX or by running the following command.
d3x serve list
To deploy a finetuned LLM registered in MLFlow in your workspace, use the steps provided below:
To list all LLMs registered in MLFlow, use the following command.
d3x models listTo deploy a finetuned LLM registered in MLFlow, use the following command. Replace the parts enclosed within <> with the appropriate details.
Note
In case you are using a EKS setup, please change the value of the flag --type from a10 to g5.4xlarge in the following command.
d3x llms deploy -n <name of the deployment> --base_model <base LLM name> --mlflow <name of registered model>:<model version> --type <GPU type> --token <access token for the model (if required)>d3x llms deploy -n llama27bft --base_model meta-llama--Llama-2-7b-chat-hf --mlflow llama27b:1 --type a10 --token hf_AhqzkVljohkypWefhrytikRzSgaXjzjWmOYou can check the status of the deployment from the Deployment page in DKubeX or by running the following command.
d3x serve list