Quickstart¶
To get started on building a custom chat application using RAG, a base LLM and an LLM finetuned with your private data, please go through the steps provided below. You can build a sample chat application by following the steps provided below.
Deploy an RAG-based Chatbot application with base LLM summarization
Deploy an RAG-based Chatbot application with finetuned LLM summarization
Prerequisites¶
You must have the current version of DKubeX installed into your system. For detailed instructions regarding installation and logging in to DKubeX, please refer to Installation.
For this example, ideally you need a a10 GPU (g5.4xlarge) node attached to your cluster.
Attention
In case of a RKE2 setup, please make sure that you have labeled the node as “a10”. Also, in case you are using any other type of GPU node, make sure to use the label for that node which you have put during DKubeX installation process.
Make sure you have the access and the secret token for that particular model which you are going to deploy (in this example, Llama2-7B).
Note
In the case the model you want to deploy is not in the DKubeX LLMs registry, you can also deploy LLMs directly from the HuggingFace model hub using the configuration file of that particular model. Make sure you have access to that particular model (in case the model is a private model).
For instructions on how to deploy the model from HuggingFace repository, please refer to Deploying Base LLMs.
This example uses the ContractNLI dataset throughout where required. You need to download the dataset on your DKubeX workspace.
Attention
Although the ContractsNLI dataset is in accordance with the terms and conditions of the Creative Commons Attribution 4.0 International Public License, it is recommended to go through the terms and conditions of the dataset before using it. You can read the terms and conditions here- https://stanfordnlp.github.io/contract-nli/#download
To download the dataset, open the Terminal application from the DKubeX UI and run the following command:
wget https://stanfordnlp.github.io/contract-nli/resources/contract-nli.zipUnzip the downloaded file using the following command. A folder called contract-nli will be created which will contain the entire dataset. Also at this point, remove the unnecessary files from the dataset folder.
unzip contract-nli.zip && cd contract-nli rm -rf dev.json LICENSE README.md TERMS test.json train.json
Data ingestion using an open-source embedding model¶
Note
For detailed information regarding this section, please refer to Data ingestion and creating dataset.
Important
This example uses the MPNET-v2 embeddings model for data ingestion.
Open the Terminal application in DKubeX UI.
Export the following variables to your workspace by running the following commands on your terminal.
Replace the <your huggingface token> part with your Huggingface token. Replace the <your huggingface token> part with your Huggingface token, and <username> with your DKubeX workspace name.
export PYTHONWARNINGS="ignore" export OPENAI_API_KEY="dummy" export HF_TOKEN="<your huggingface token>" export NAMESPACE="<username>" export HOMEDIR=/home/${NAMESPACE}
Use the following command to perform data ingestion and create the dataset. A dataset named contracts will be created.
d3x fm docs add -d contracts -s ./contract-nli -emb mpnet-v2Note
A few documents from the ContractsNLI dataset may show errors during the ingestion process. This is expected behaviour ar those documents’ format are not suitable for ingestion.
Attention
The time taken for the ingestion process to complete depends on the size of the dataset. The ContractsNLI dataset contains 605 documents and the ingestion process may take around 30 minutes to complete. Please wait patiently for the process to complete.
In case the terminal shows a timed-out error, that means the ingestion is still in progress, and you will need to run the command provided on the CLI after the error message to continue to get the ingestion logs.
To check if the dataset has been created, stored and are ready to use, use the following command:
d3x fm docs show datasetsTo check the list of documents that has been ingested in the dataset, use the following command:
d3x fm docs show docs -d contracts
Deploy a base LLM model from DKubeX LLM Registry¶
Note
For detailed information regarding this section, please refer to Deploying LLMs in DKubeX.
Here we will deploy the base Llama2-7B model, which is already pre-registered with DKubeX.
Note
This workflow requires an a10 GPU node. Make sure your cluster is equipped with such. Also, in case you are using any other type of GPU node, make sure to use the label for that node which you have put during DKubeX installation process.
Note
This example requires a Huggingface token for using the Llama2-7b model. Make sure you have access token for the model that you are serving.
To list all LLM models registered with DKubeX, use the following command.
d3x llms listDeploy the base Llama2-7B model using the following command.
d3x llms deploy --name=llama2base --model=meta-llama--Llama-2-7b-chat-hf --type=a10 --token ${HF_TOKEN}Note
In case you are using a EKS setup, please change the value of the flag --type from a10 to g5.4xlarge in the following command. Also, in case you are using any other type of GPU node, make sure to use the label for that node which you have put during DKubeX installation process.
You can check the status of the deployment from the Deployments page in DKubeX or by running the following command.
d3x serve listWait until the deployment is in running state.
Deploy an RAG-based Chatbot application with base LLM summarization¶
Note
For detailed information regarding this section, please refer to Creating and accessing the chatbot application.
From the DKubeX UI, open and log into the SecureLLM application. Once open, click on the Admin Login button and log in using the admin credentials provided during installation.
Hint
In case you do not have the credentials for logging in to SecureLLM, please contact your administrator.
On the left sidebar, click on the Keys menu and go to the Application Keys tab on that page.
To create a new key for your application, use the following steps:
On the API key name field, provide a unique name for the key to be created.
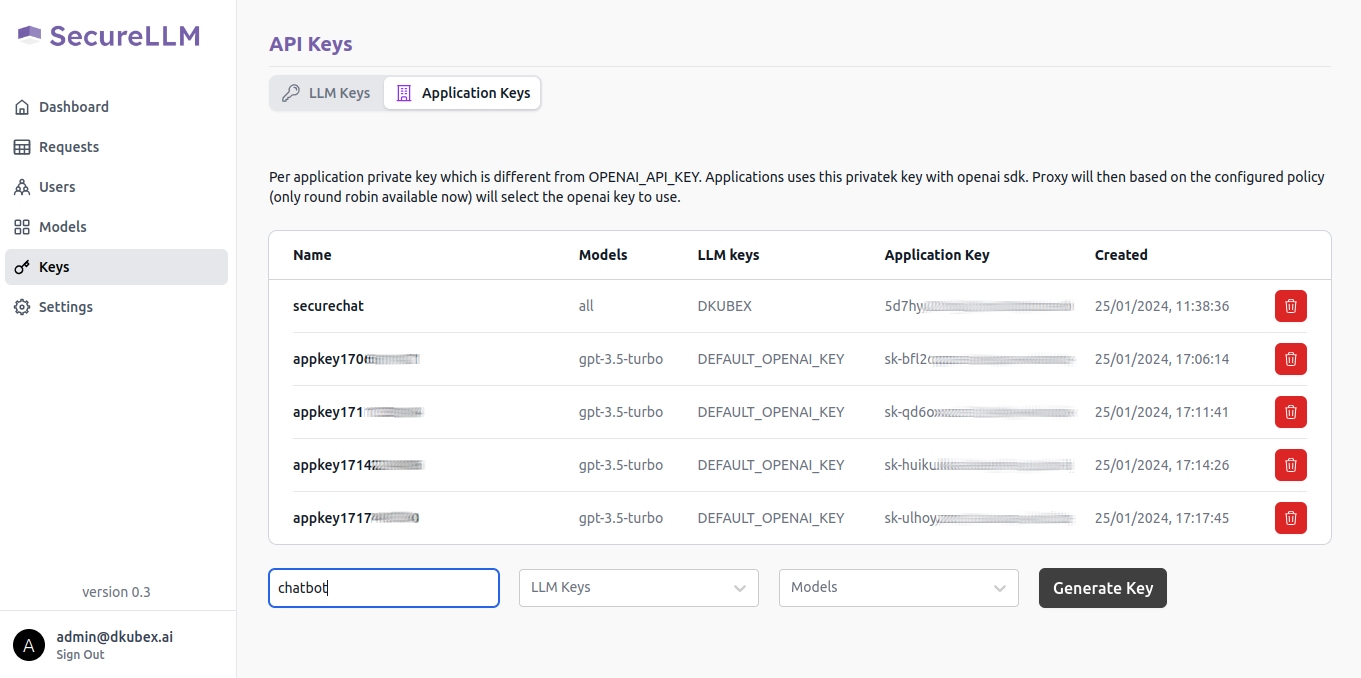
From the LLM Keys dropdown list, select DKUBEX.
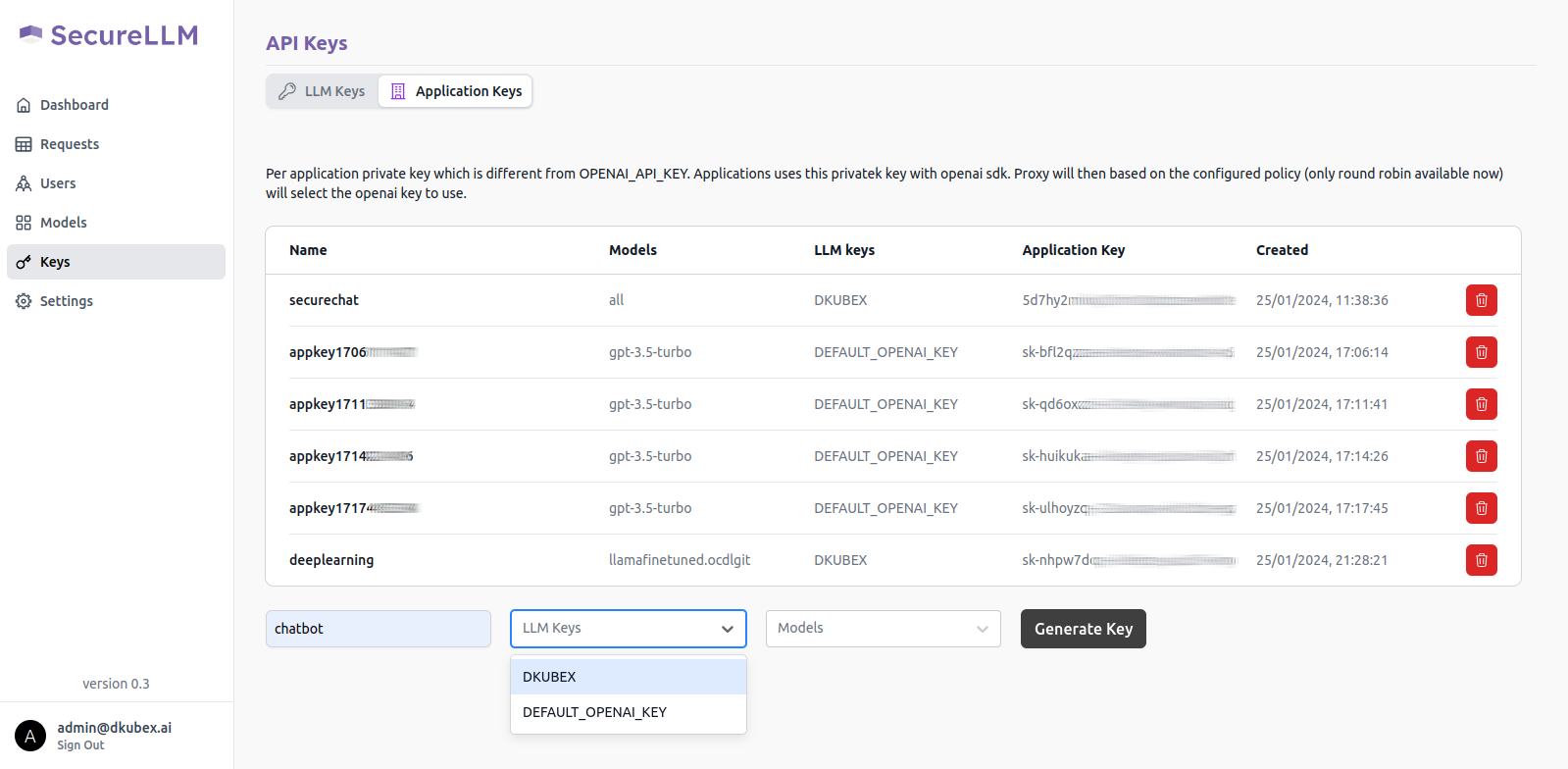
From the Models dropdown list, select your deployed base model.
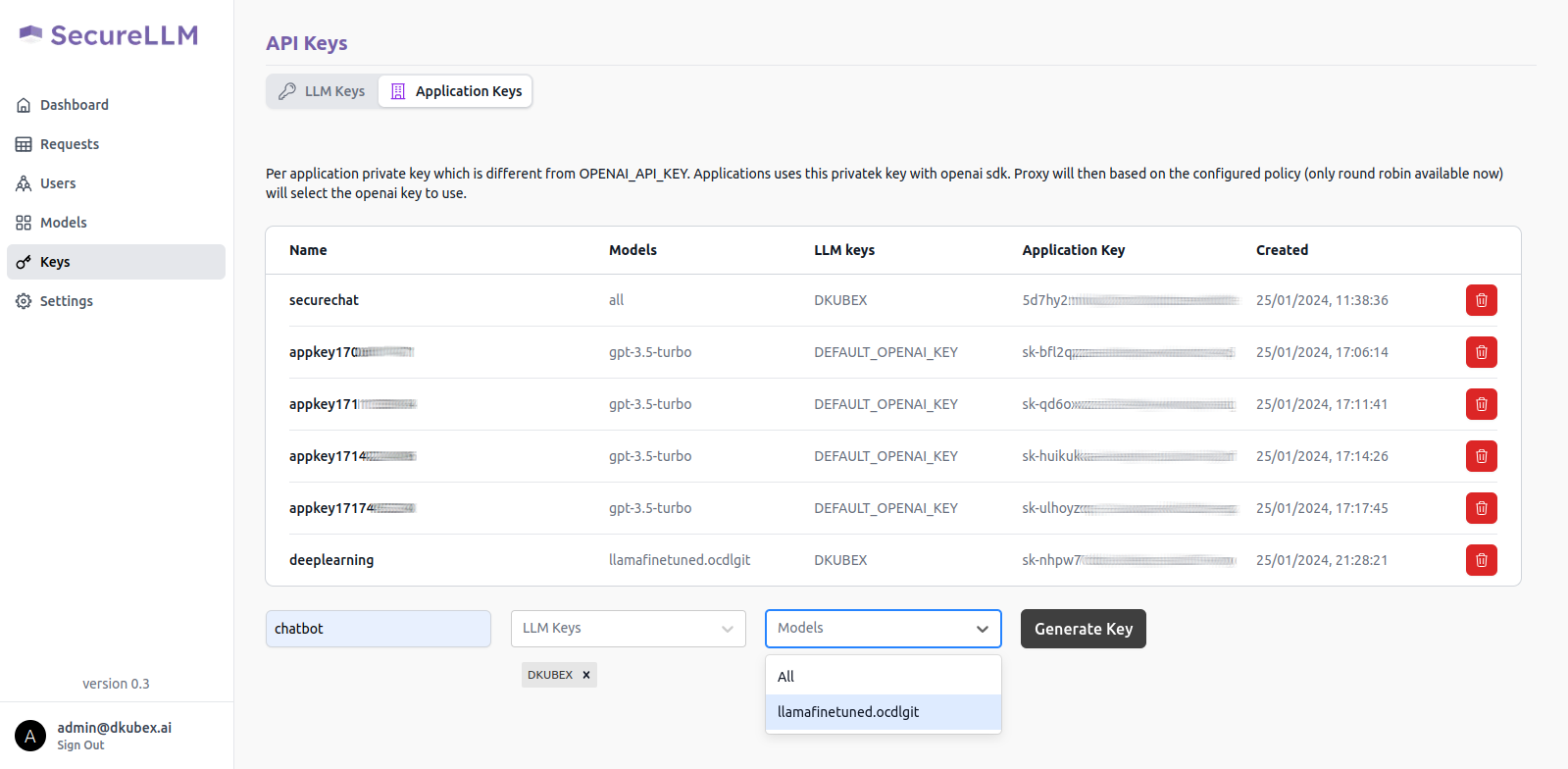
Click on the Generate Key button.
A pop-up window will show up on your screen containing the application key for your new application. Alternatively, you can also access your application key from the list of keys in the Application Key tab.
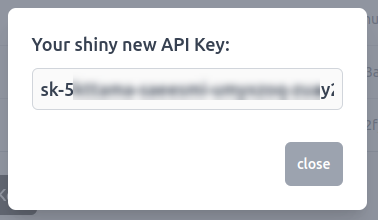
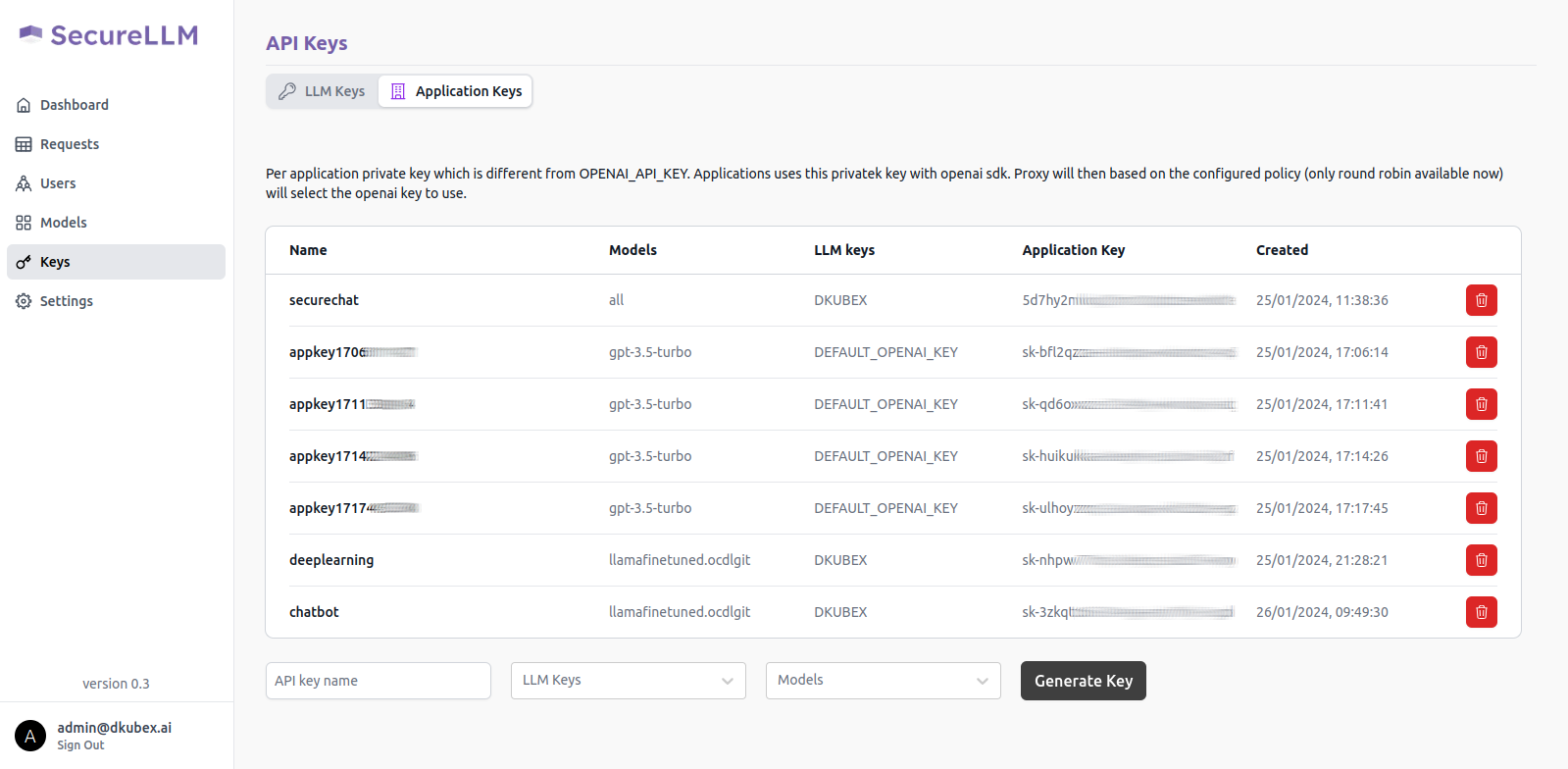
Copy this application key for further use, as it will be required to create the chatbot application. Also make sure that you are copying the entire key including the sk- part.
From the DKubeX UI, go to the Terminal application.
To create the chatbot application, use the following command.
Important
Make sure you replace the following in the command-
sk-xxxxxxx-xxxxxxx-xxxxxxx-xxxxxxx part with the application key generated earlier in SecureLLM.
The SECUREAPP_ACCESS_KEY field in the command is the password which will be asked once you open the chatbot application.
The -dep flag under FMQUERY_ARGS is the name of the base LLM model that you deployed earlier.
d3x apps create --name=ndabase -e OPENAI_API_KEY=sk-xxxxxxx-xxxxxxx-xxxxxxx-xxxxxxx -e APP_TITLE=Contracts -e SECUREAPP_ACCESS_KEY=allow -e FMQUERY_ARGS="llm -dep llama2base -d contracts -emb mpnet-v2 -g -n ${NAMESPACE}" -p 3000 --dockeruser=dkubex123 --dockerpsw=dckr_pat_dE90DkE9bzttBinnniexlHdPPgI -rt false -ip /ndabase --publish=true --memory=4 --cpu=1 dkubex123/llmapp:securechat-0.7.9.1To check the status of the app deployment, use the following command:
d3x apps listOnce the app deployment status becomes running, you can access the application from the Apps page of DKubeX UI. Provide the application key that you set in the SECUREAPP_ACCESS_KEY field earlier to start using the chat application.
Hint
You can ask the following questions to the chatbot when using the ContractsNLI dataset:
How do I frame a confidential information clause?
What is the difference between a unilateral and mutual NDA?
What are some common exceptions to confidential information clauses?
Finetune an open-source LLM with custom dataset¶
Note
For detailed information regarding this section, please refer to Finetuning Open Source LLMs.
Export the following variables to your workspace by running the following commands. Replace the <your huggingface token> part with your Huggingface token, and <username> with your DKubeX workspace name.
export PYTHONWARNINGS="ignore" export OPENAI_API_KEY="dummy" export HF_TOKEN="<your huggingface token>" export NAMESPACE="<username>" export HOMEDIR=/home/${NAMESPACE}
Break the documents down from the folder provided to create chunks using the following command:
d3x fm docs create-chunks --source ./contract-nli/ --destination ./chunks/ -c 500Note
A few documents from the ContractsNLI dataset may show errors during the create-chunks process. This is expected behaviour ar those documents’ format are not suitable for ingestion.
Split the chunks into test and train data by using the following command:
d3x fm trainchunks --source ./chunks_for_finetuning/ --destination ./train-chunks/Train the chunks with the LLM using the following command:
Note
In case you are using a EKS setup, please change the value of the flag -t from a10 to g5.4xlarge. Also, in case you are using any other type of GPU node, make sure to use the label for that node which you have put during DKubeX installation process.
d3x fm tune model finetune -j llama2finetuning -e 1 -b 20 -l ${HOMEDIR}/train-chunks -o ${HOMEDIR}/ft-output/ -c 8 -m 64 -g 1 -t a10 -n meta-llama/Llama-2-7b-chat-hf --ctx-len 512Attention
The time taken by the finetuning process depends on the size of the dataset. The ContractsNLI dataset contains 605 documents and the finetuning process may take around one hour to complete. Please wait patiently for the process to complete.
In case the terminal shows a timed-out error, that means the finetuning is still in progress, and you will need to run the command provided on the CLI after the error message to continue to get the finetuning logs.
You will need the absolute path to the finetuned model checkpoint to merge the finetuned model with the base model. Use the following command to get the absolute path to the finetuned model checkpoint:
echo ${HOME}/ft-output/meta-llama/Llama-2-7b-chat-hf/TorchTrainer_*/TorchTrainer_*/checkpoint*/Export the absolute path to the finetuned model checkpoint to be used during the merge process with the following command. export the <checkpoint absolute path> part with the absolute path to the finetuned model checkpoint you got in the previous step.
export CHECKPOINT="<checkpoint absolute path>"
Merge the finetuned model checkpoint with the base model to create the final finetuned model using the following command:
Note
In case you are using a EKS setup, please change the value of the flag -t from a10 to g5.4xlarge. Also, in case you are using any other type of GPU node, make sure to use the label for that node which you have put during DKubeX installation process.
d3x fm tune model merge -j $merge job name$ -n $full HF path to the base model$ -cp $absolute path to the finetuned checkpoint$ -o $absolute path to merged finetuned model output folder$ -t a10d3x fm tune model merge -j llama2merge -n meta-llama/Llama-2-7b-chat-hf -cp ${CHECKPOINT} -o ${HOMEDIR}/merge_output -t a10To quantize the finetuned model, use the following command:
Note
In case you are using a EKS setup, please change the value of the flag -t from a10 to g5.4xlarge. Also, in case you are using any other type of GPU node, make sure to use the label for that node which you have put during DKubeX installation process.
d3x fm tune model quantize -j quantize-test -p ${HOMEDIR}/merge_output/ -o ${HOMEDIR}/quantize_result -t a10Attention
The time taken by the quantization process depends on the size of the dataset. The ContractsNLI dataset contains 605 documents and the quantization process may take around 30 minutes to complete. Please wait patiently for the process to complete.
In case the terminal shows a timed-out error, that means the quantization is still in progress, and you will need to run the command provided on the CLI after the error message to continue to get the quantization logs.
Importing the finetuned LLM model to MLFlow¶
Note
For detailed information regarding this section, please refer to Deploying LLMs in DKubeX.
To import the finetuned LLM model to MLFlow, use the following command:
d3x models import llama27bft custom_model ${HOMEDIR}/quantize_result
Deploy the finetuned LLM model from MLFlow¶
Note
For detailed information regarding this section, please refer to Deploying LLMs in DKubeX.
Deploy the finetuned LLM model using the following command:
Note
In case you are using a EKS setup, please change the value of the flag --type from a10 to g5.4xlarge in the following command. Also, in case you are using any other type of GPU node, make sure to use the label for that node which you have put during DKubeX installation process.
d3x llms deploy -n llama2ft --mlflow llama27bft:1 --token ${HF_TOKEN} --type a10 --base_model meta-llama--Llama-2-7b-chat-hfCheck the status of the deployment from the Deployment page in DKubeX or by running the following command. Wait until the deployment is in Running state.
d3x serve list
Deploy an RAG-based Chatbot application with finetuned LLM summarization¶
Note
For detailed information regarding this section, please refer to Creating and accessing the chatbot application.
From the DKubeX UI, open and log into the SecureLLM application. Once open, click on the Admin Login button and log in using the admin credentials provided during installation.
Hint
In case you do not have the credentials for logging in to SecureLLM, please contact your administrator.
On the left sidebar, click on the Keys menu and go to the Application Keys tab on that page.
To create a new key for your application, use the following steps:
On the API key name field, provide a unique name for the key to be created.
From the LLM Keys dropdown list, select DKUBEX.
From the Models dropdown list, select your deployed finetuned model.
Click on the Generate Key button.
A pop-up window will show up on your screen containing the application key for your new application. Alternatively, you can also access your application key from the list of keys in the Application Key tab.
Copy this application key for further use, as it will be required to create the chatbot application. Also make sure that you are copying the entire key including the sk- part.
From the DKubeX UI, go to the Terminal application.
To create the chatbot application, use the following command.
Important
Make sure you replace the following in the command-
sk-xxxxxxx-xxxxxxx-xxxxxxx-xxxxxxx part with the application key generated earlier in SecureLLM.
The SECUREAPP_ACCESS_KEY field in the command is the password which will be asked once you open the chatbot application.
The -dep flag under FMQUERY_ARGS is the name of the finetuned LLM model that you deployed earlier.
d3x apps create --name=ndaft -e OPENAI_API_KEY=sk-xxxxxxx-xxxxxxx-xxxxxxx-xxxxxxx -e APP_TITLE=Contracts -e SECUREAPP_ACCESS_KEY=allow -e FMQUERY_ARGS="llm -dep llamafinetuned -d contracts -emb mpnet-v2 -g -n ${NAMESPACE}" -p 3000 --dockeruser=dkubex123 --dockerpsw=dckr_pat_dE90DkE9bzttBinnniexlHdPPgI -rt false -ip /ndaft --publish=true --memory=4 --cpu=1 dkubex123/llmapp:securechat-0.7.9.1To check the status of the app deployment, use the following command:
d3x apps listOnce the app deployment status becomes running, you can access the application from the Apps page of DKubeX UI. Provide the application key that you set in the SECUREAPP_ACCESS_KEY field earlier to start using the chat application.
Hint
You can ask the following questions to the chatbot when using the ContractsNLI dataset:
How do I frame a confidential information clause?
What is the difference between a unilateral and mutual NDA?
What are some common exceptions to confidential information clauses?
Tutorials and More Information¶
For more examples including how to train and register models and deploy user applications, please visit the following pages and go through the table provided:
Training Fashion MNIST model in DKubeX
Finetuning open-source LLMs
Deploying models registered in MLFlow in DKubeX
Deploying models from Huggingface repo
Deploying LLM registered in DKubeX
Creating a Securechat App using MPNET-v2 Embeddings and Llama2-7b Summarisation Models
Creating a Securechat App using OpenAI Embeddings and OpenAI Summarisation Models
Wine Model Finetuning using Skypilot
Llama2 Finetuning using SkyPilot