Training Models and Open-source LLMs¶
Training models can be done from the CLI provided by the Terminal app on DKubeX. You can find this app on the Apps page on DKubeX UI.
The training examples available in the user guide are listed below. To go to the particular example or tutorial you are looking for, please click on the link provided beside it.
Example |
Link |
|---|---|
Training Fashion MNIST model in DKubeX |
|
Finetuning open-source LLMs |
Training Fashion MNIST model in DKubeX¶
The Fashion MNIST dataset serves as a sizable collection of freely accessible fashion-related images, widely employed for training and evaluating diverse machine learning systems. To train and register a model with the Fashion MNIST dataset in DKubeX, please follow the steps provided below.
Create Ray cluster¶
To see which Ray clusters are available to work, enter the following command and press Enter.
d3x ray listThis will list all the currently available Ray clusters.
If there are no Ray clusters available to work on, use the following command to create a new Ray cluster. Replace the $cluster_name$ with the name the cluster will be provided. You can also mention the resource specifications of the cluster here. For more information about this, check the d3x Commands page.
d3x ray create -n $cluster_name$
d3x ray create -n mnist --cpu=4 --memory=8 --hcpu=4 --hmemory=8
Activate Ray cluster¶
To activate the cluster that you are going to use, use the following command. Replace $cluster_name$ with the name of the cluster.
d3x ray activate $cluster_name$
d3x ray activate mnist
To check whether the cluster has been activated successfully, run the following command [The currently available clusters will be listed on the CLI, on which the active cluster name should have an asterisk (*) symbol beside it.]:
d3x ray list
Create a training job¶
You’ll need to access the GitHub repo containing the training files and clone it to your workspace. For this example, you can use the dkubex-examples GitHub repository. Clone the repo to your workspace using the following command:
git clone https://github.com/dkubeio/dkubex-examples.gitChange the directory containing the model training file. For this example, move to the dkubex-examples/ray folder by using the following:
cd dkubex-examples/rayTo run a Ray job to train your model, use the following command. The training job will start and the logs will be shown on the screen. Before running the command, replace the following in the command.
$dir$: directory containing files your job will run in
$runtimejson$: JSON-serialized runtime_env dictionary.
$file_name$: name of the model file
d3x ray job submit --working-dir $dir$ --runtime-env-json='$runtimejson$' -- python $file_name$
d3x ray job submit --working-dir $PWD --runtime-env-json='{"pip": ["torch", "torchvision"]}' -- python mnist_without_ray.py
Once the job has ended, it will show Job ‘raysubmit_<job_id>’ succeeded.
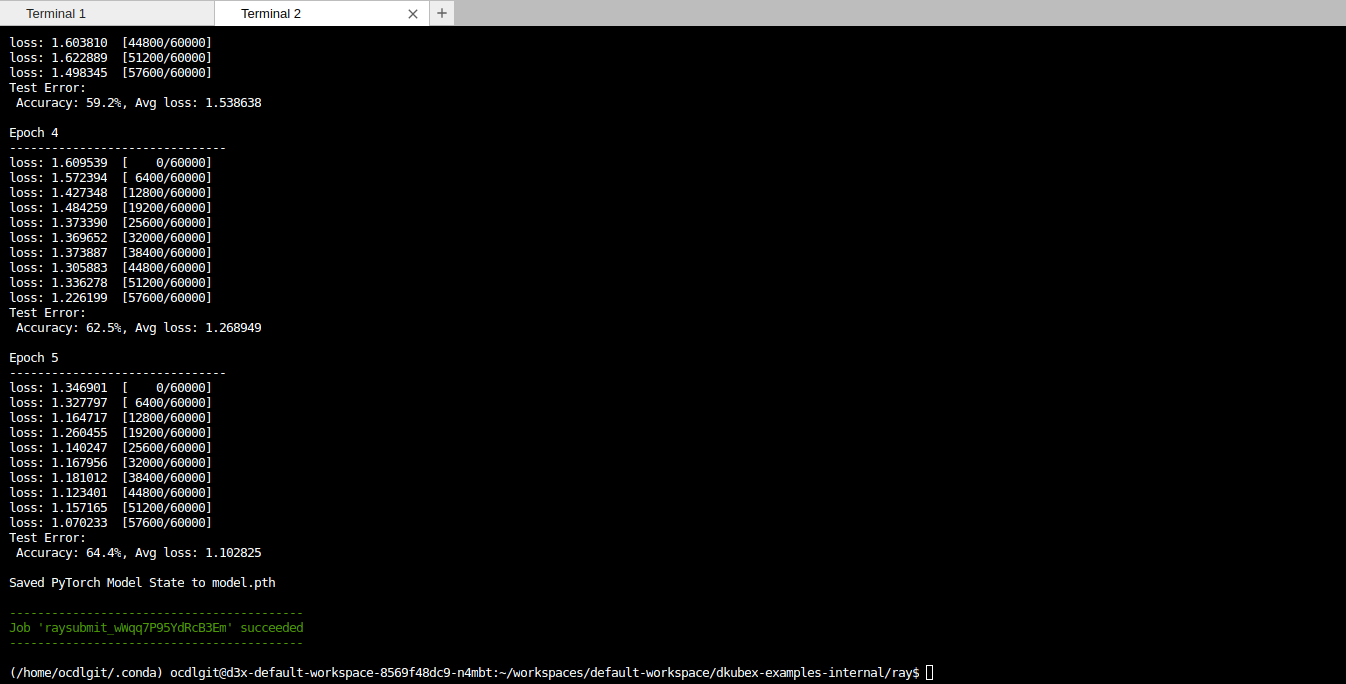
Access Ray job details on MLFlow¶
Open the MLFlow app in DKubeX UI.
Click on the job that you are searching the details for from the list of Experiments. The page containing the details for that job will open.
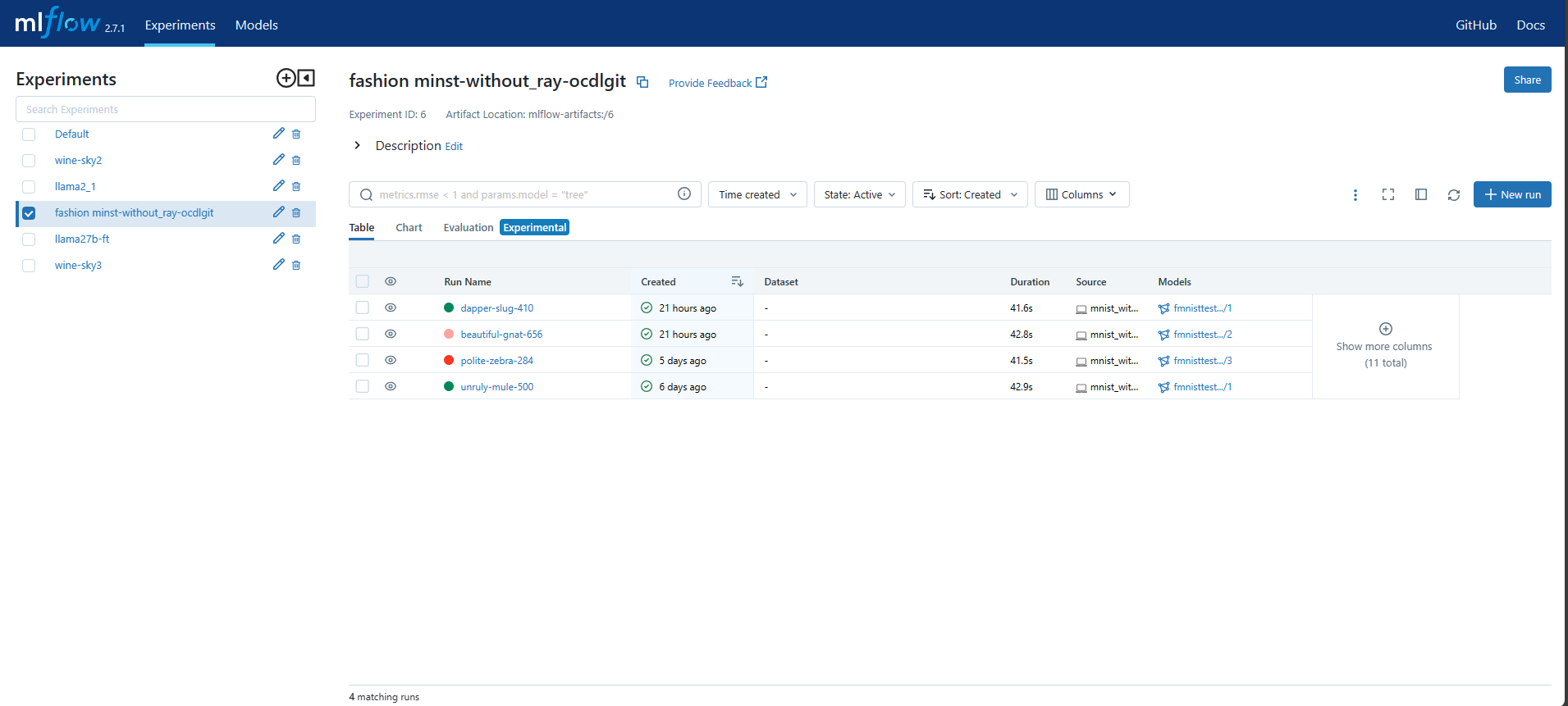
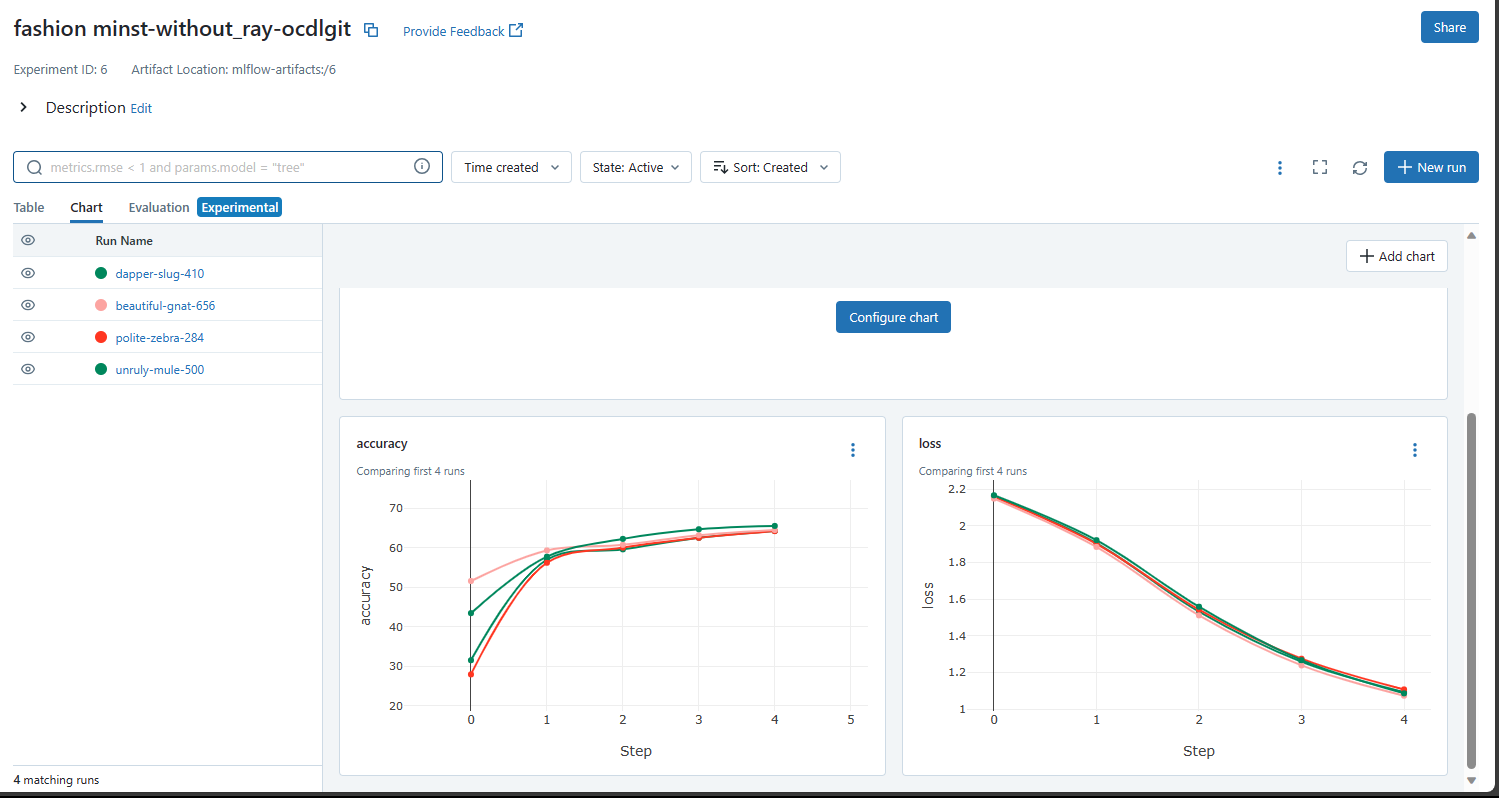
This page lists all the runs that have been done in this Ray job and the models that have been generated from these runs. The default view is Table view, but for comparison of these runs chart view and artifact view is also available.
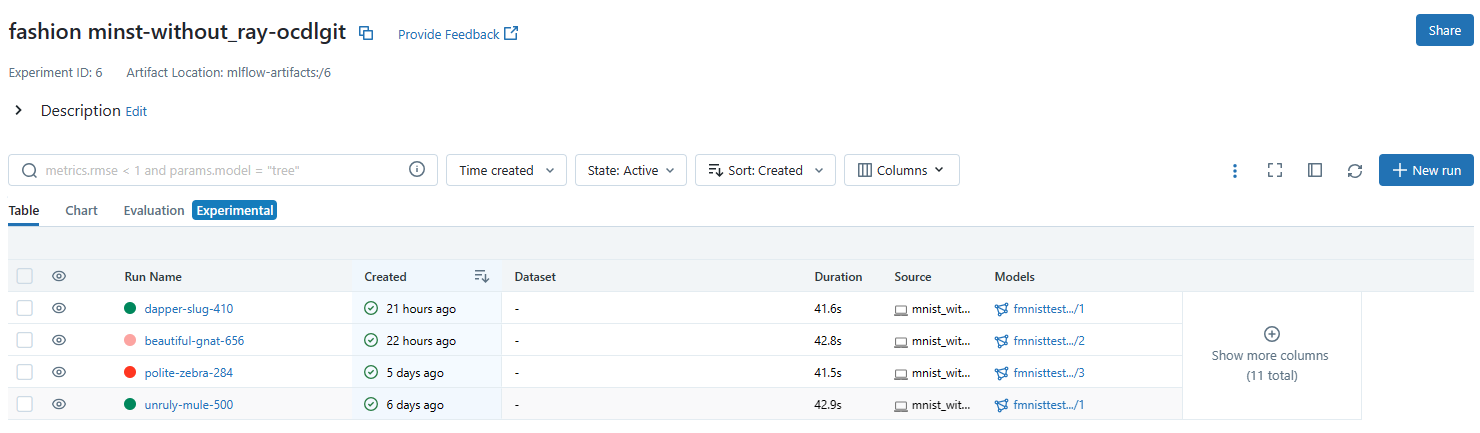
To compare two or more runs, use the following steps-
Select the runs you want to compare by clicking on the checkboxes beside them, and then click on the compare button.
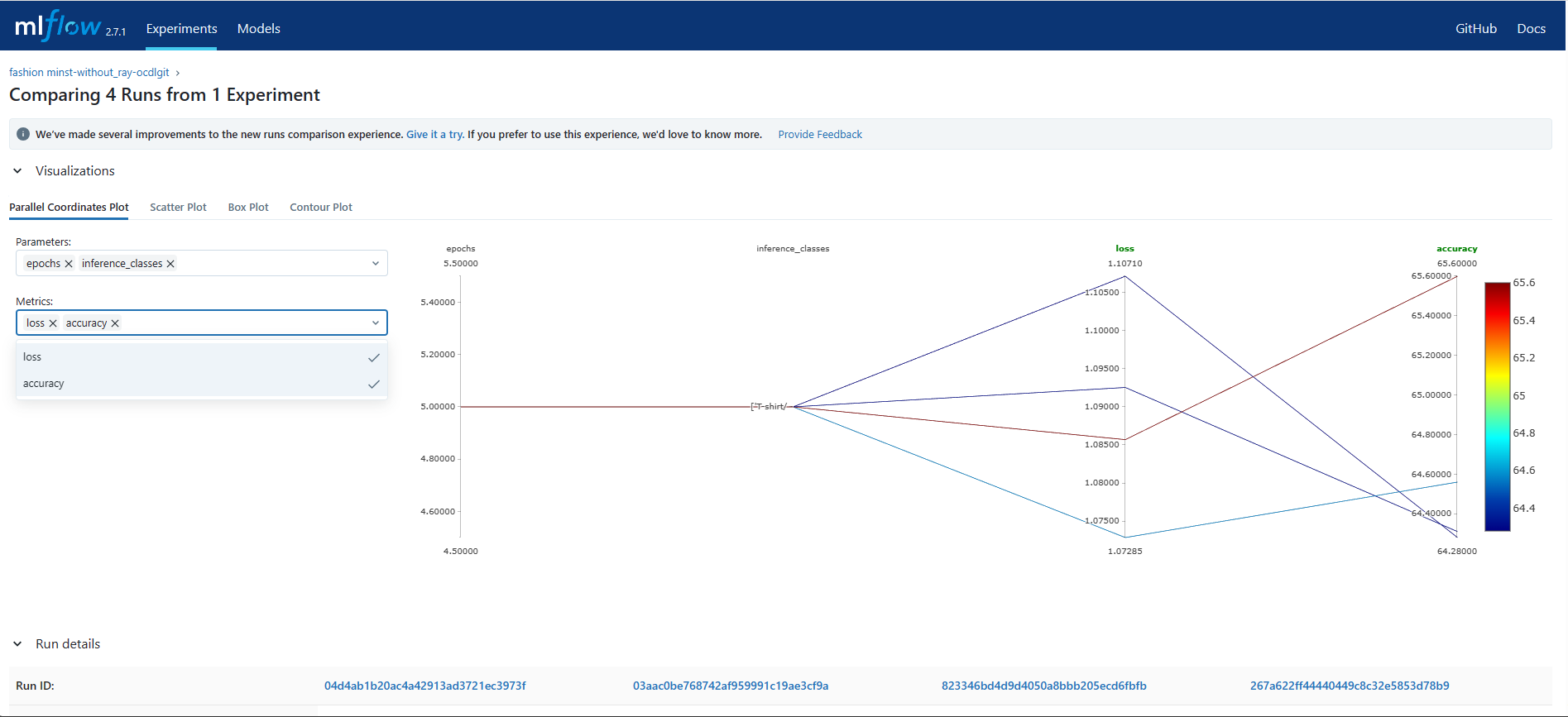
The comparisons page will open. Select the type of plot, parameters and metrics that you want to visualize.
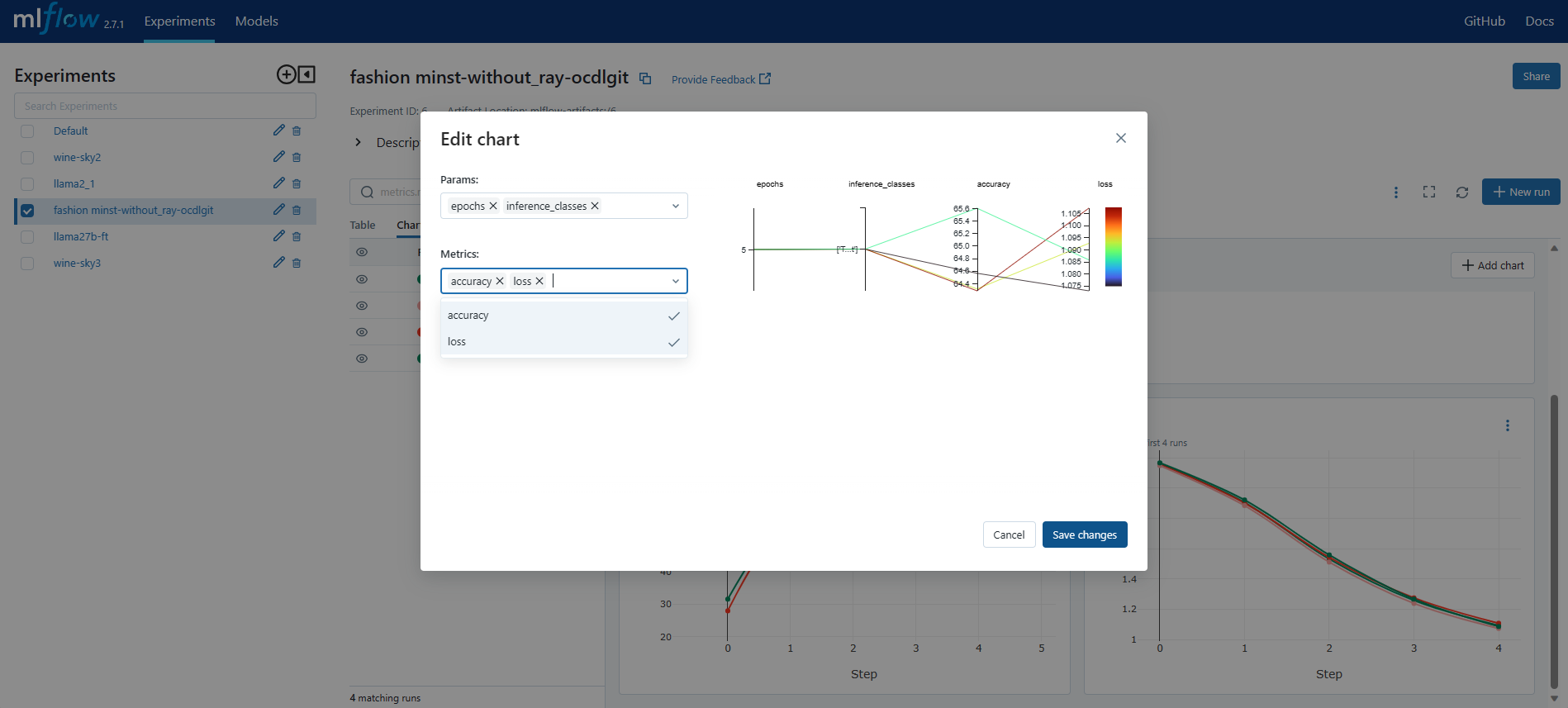
You can also compare the runs by selecting them and opening Chart view, clicking on the Configure Chart button, and selecting the appropriate parameters and metrics, and clicking on Save Changes button.
Register Trained Model on MLFlow¶
Open the MLFlow tab in DKubeX UI.
On the Experiments page, click on the experiment on which the new trained model was created. The page having the details of that job will be displayed.
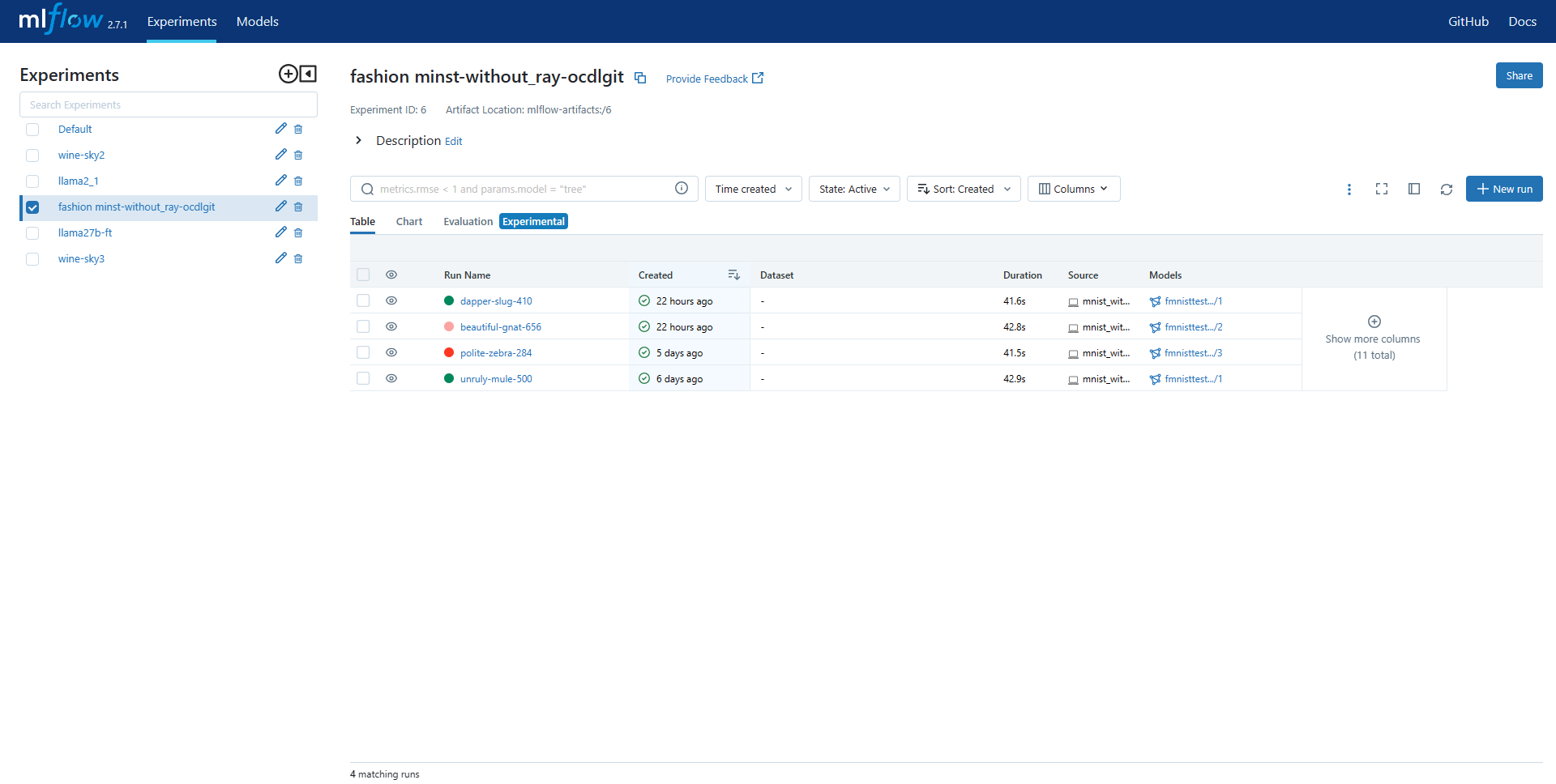
Click on the run name on which the model was generated. You can identify this by looking on the Models column and find the run which has your desired model. The page containing the details of that run will be displayed.
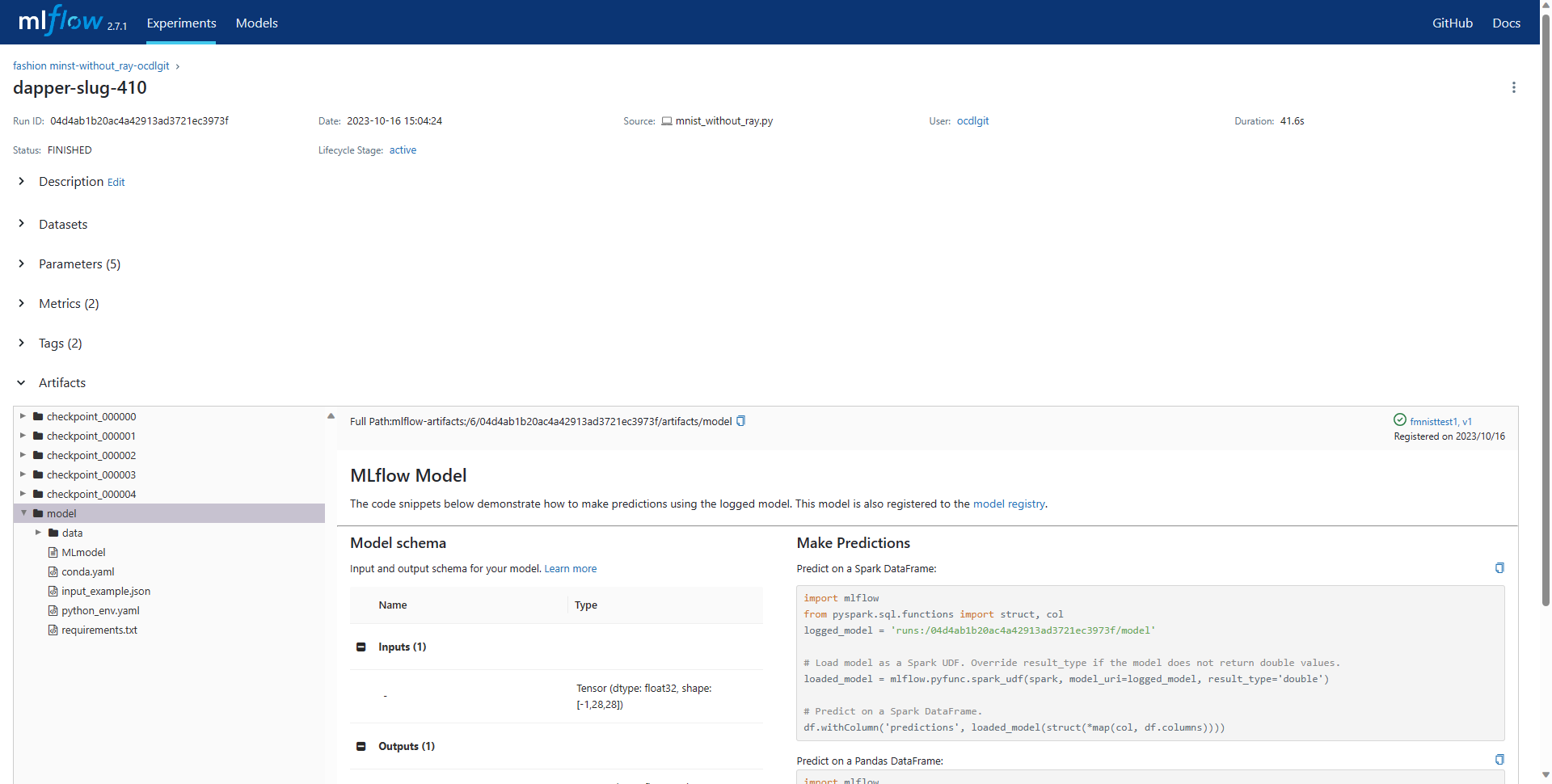
In the Artifacts section on this page, the details about this model will be shown. Click on the Register Model button to register it to the MLFlow model registry.
On the Register Model pop-up screen, click on the Create New Model option from the Model dropdown menu, and then provide an unique name to the model in the Model Name field. Once you are done, click on the Register button.
To check whether the model has been successfully registered, open the Models page in the MLFlow tab. Your model should be visible in the list of registered models.

Finetuning Open Source LLMs¶
Fine-tuning Large Language Models (LLMs) refers to the process of retraining a pre-trained language model on a specific task or dataset to adapt it for a particular application. In this example, the Llama2-7b model is finetuned using data-chunks from a set of documents.
Prerequisites¶
Create a folder in the workspace and provide the documents that are going to be chunked to be used for model finetuning using the Filebrowser application in DKubeX UI.
This workflow requires an a10 GPU node. Make sure your cluster is equipped with such.
Finetuning workflow¶
To finetune an LLM supported by DKubeX, Follow these steps:
Break the documents down from the folder provided to create chunks using the following command.
d3x fm docs create-chunks --source $path to documents folder$ --destination $path to new chunks folder$ -c $chunk_size$
d3x fm docs create-chunks --source ./contracts/ --destination ./chunks/ -c 500
Split the chunks into test and train data:
d3x fm trainchunks --source $finetuning chunks folder path$ --destination $training chunks folder path$
d3x fm trainchunks --source ./chunks_for_finetuning/ --destination ./train-chunks/
Finetune the LLM with the chunks using the following command.
d3x fm tune model finetune -j $name of finetuning job$ -e $number of epochs$ -b $batch size$ -l $training chunks folder path$ -o $output folder path$ -c $CPU$ -m $memory$ -g $GPU$ -t $instance type$ -n $name of model to be finetuned$ --ctx-len $context length$
d3x fm tune model finetune -j llama2finetuning-1 -e 1 -b 20 -l /home/ocdlgit/finetuning/train-chunks -o /home/ocdlgit/finetuning/ft-output/ -c 8 -m 64 -g 1 -t a10 -n meta-llama/Llama-2-7b-chat-hf --ctx-len 512
Note
In case of setups brought up on a Rancher cluster, the -t or --type option in this command denotes the node or instance type which you have provided in the Installing DKubeX section.
Merge the finetuned model checkpoint with the base model to create the final finetuned model using the following command:
d3x fm tune model merge -j $merge job name$ -n $full HF path to the base model$ -cp $absolute path to the finetuned checkpoint$ -o $absolute path to merged finetuned model output folder$d3x fm tune model merge -j llama2merge -n meta-llama/Llama-2-7b-chat-hf -cp /home/ocdlgit/ft-output/meta-llama/Llama-2-7b-chat-hf/TorchTrainer_2024-01-09_02-59-34/TorchTrainer_2c6e1_00000_0_2024-01-09_02-59-34/checkpoint_000000/ -o /home/ocdlgit/merge_outputTo quantize the finetuned model, use the following command:
d3x fm tune model quantize -j $quantization job name$ -p $absolute path to merged finetuned model$ -o $absolute path to quantized model output folder$d3x fm tune model quantize -j quantize-test -p /home/ocdlgit/merge_output/ -o /home/ocdlgit/quantize_result