Data Ingestion and Deploying RAG-based chatbot¶
Retrieval Augmented Generation is a great way to leverage your private corpus with generative AI & when combined with fine-tuned LLMs, you can achieve GPT-like results for your custom use cases.
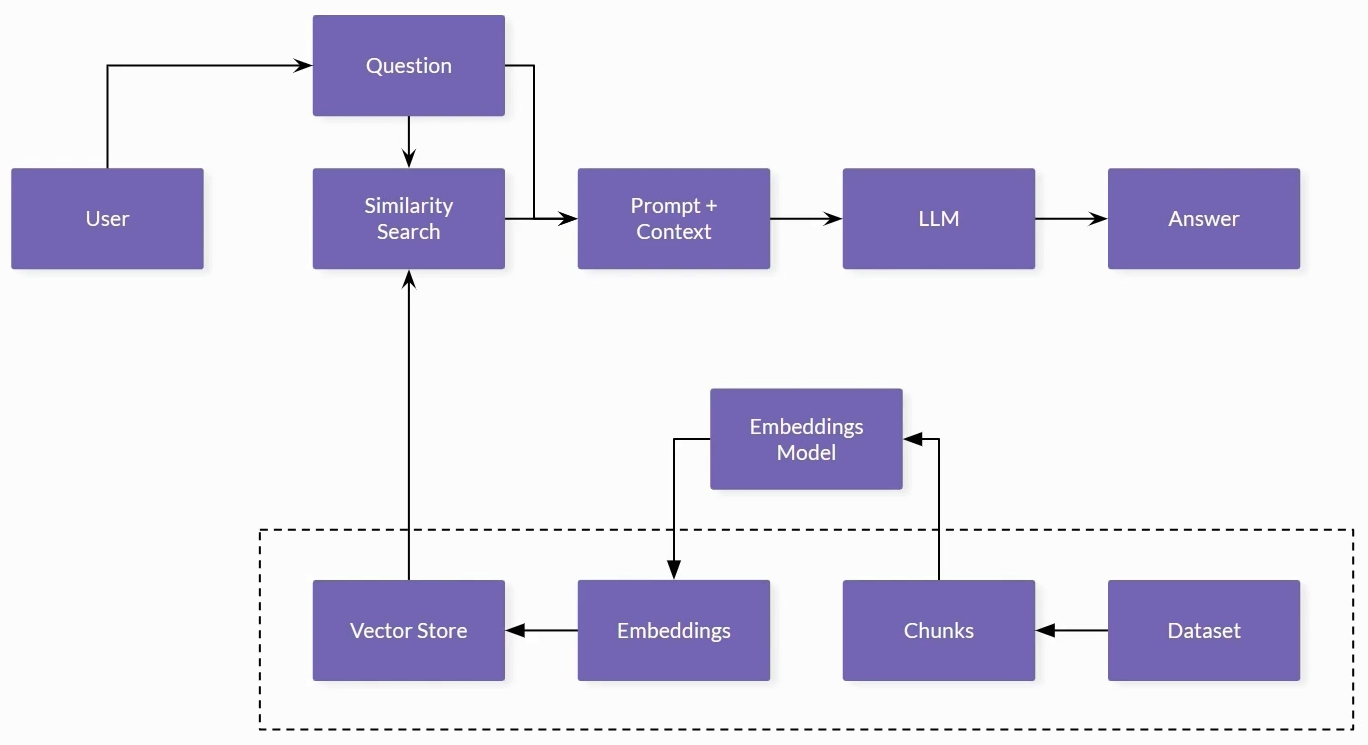
In this workflow, datasets (PDF, DOCX, TXT, HTML) are first divided into smaller segments or chunks. These chunks are then transformed into embeddings using an embeddings module and then stored in a vector database for efficient retrieval.
When a user submits a query in a chat application, the backend system conducts a search to find relevant context. It combines this context with a custom prompt and utilizes a Language Model (LLM) acting as a summarization agent. The LLM’s role is to generate human-like responses to the query, ensuring that the answers are coherent and contextually relevant.
The following example will take you through the procedure of deploying a LLM chatbot that can answer questions based on specific dataset(s) provided by you.
Examples |
|---|
Creating a Securechat App using BGE-large Embedding and base Llama-3-8b Summarisation Models |